0x00 概述
在google搜索Expression Language时,发现在维基百科中相关的词条叫做“统一表达式语言”。再次词条的引用部分,被一行内容吸引到:
MVEL - 一个被众多Java项目使用的开源的表达式语言。
最流行的内容研究的现阶段价值也就最大,攻防更是如此。所以,我打算在JWEI的研究中,先拿它来开刀。
本篇文章将针对MVEL解析表达式的过程进行简单的分析,来帮助我们在未来的研究中探索这种表达式的特性。
0x01 MVEL表达式执行方法
MVEL运行时提供给使用者两种使用模式——解释模式和编译模式。解释模式是一种无状态的即时编译并执行的特设模式,不会产生中间产物,但是表达式执行的速度会减慢。编译模式会产生大量的编译中间产物,用于缓存和预执行,但是执行速度比解释模式更快。
以上是官方文档中向使用者描述的两种使用方法,下面我们来看下,官方对于这两种模式的实现示例。
解释模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| import org.mvel.MVEL; public class MVELTest { public static void main(String[] args) { String expression = "foobar > 99"; Map vars = new HashMap(); vars.put("foobar", new Integer(100)); Boolean result = (Boolean) MVEL.eval(expression, vars); if (result.booleanValue()) { System.out.println("It works!"); } } }
|
编译模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| import org.mvel.MVEL; public class MVELTest2 { public static void main(String[] args) { String expression = "foobar > 99"; Serializable compiled = MVEL.compileExpression(expression); Map vars = new HashMap(); vars.put("foobar", new Integer(100)); Boolean result = (Boolean) MVEL.executeExpression(compiled, vars); if (result.booleanValue()) { System.out.println("It works!"); } } }
|
除了上面的两种调用方法,我在看ElasticSearch代码时,发现它使用了另外的一种方法,来实现MVEL的执行。这种方法属于编译模式,我的测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| import java.io.IOException; import java.util.HashMap; import java.util.Map; import org.mvel2.MVEL; import org.mvel2.compiler.ExecutableStatement; import org.mvel2.integration.impl.MapVariableResolverFactory; public class MvelDemo { public static void main(String[] args) { String expression = "foobar > 99"; String str = "a=123"; String exp = ";new java.lang.ProcessBuilder(\"calc\").start();"; MapVariableResolverFactory resolver = new MapVariableResolverFactory(new HashMap()); Map vars = new HashMap(); vars.put("foobar", new Integer(100)); ExecutableStatement script = (ExecutableStatement) MVEL.compileExpression(str+exp); script.getValue(null,resolver); } }
|
即通过编译后的内容可以转换成ExecutableStatement类型,通过这种类型的getValue方法,也是可以执行表达式内容的。
0x02 解析执行过程
我们分析过程中用来测试的表达式是:“a=123;new java.lang.ProcessBuilder(“calc”).start();”。
测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| import java.io.IOException; import java.util.HashMap; import java.util.Map; import org.mvel2.MVEL; import org.mvel2.compiler.ExecutableStatement; public class MvelDemo { public static void main(String[] args) { String exp = "a=123;new java.lang.ProcessBuilder(\"calc\").start();"; Map vars = new HashMap(); vars.put("foobar", new Integer(100)); String result = MVEL.eval(exp, vars).toString(); } }
|
首先进入到MVEL中的eval方法中,在这个方法中初始化MVELInterpretedRuntime类,并且调用它的parse方法。在parse方法中最主要的步骤是调用parseAndExecuteInterpreted方法,这个方法是解释模式中最终处理表达式执行的方法。我们来看它最开始的一部分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| private Object parseAndExecuteInterpreted() { ASTNode tk = null; int operator; lastWasIdentifier = false; try { while ((tk = nextToken()) != null) { holdOverRegister = null; if (lastWasIdentifier && lastNode.isDiscard()) { stk.discard(); } * If we are at the beginning of a statement, then we immediately push the first token * onto the stack. */ if (stk.isEmpty()) { if ((tk.fields & ASTNode.STACKLANG) != 0) { stk.push(tk.getReducedValue(stk, ctx, variableFactory)); Object o = stk.peek(); if (o instanceof Integer) { arithmeticFunctionReduction((Integer) o); } } else { stk.push(tk.getReducedValue(ctx, ctx, variableFactory)); }
|
tk=nextToken()这条语句会将程序带入到AbstractParser这个类的nextToken方法中。而这个类的位置是org.mvel2.compiler.AbstractParser,我们在进入这个类后,可以看到下面这样的一行注释:
1 2 3 4 5
| * This is the core parser that the subparsers extend. * * @author Christopher Brock */
|
由此可见,不管使用哪种执行表达式的方法,对于表达式的解析都是由这个类来完成的。我们继续来跟进nextToken的执行过程。
初始化抓取标识capture,跳过debug这些内容,检测游标所指位置字符是否符合规范(标准的变量名),若符合则开启抓取(抓取标识置true),并且游标加一。然后判断此时游标字符是否符合规范,如果是则游标加一,不断往复。
检测游标所指之前内容是否存在NEW、IF、CONTAINS等操作关键字,我们此时的内容为a,所以跳过这个环节。skipWhitespace方法跳过回车、换行和注释等空白内容,此时游标指在“=”。
进入抓取循环,识别出当前字符为“=”,进入等号处理分支,在此分支的非操作符处理块中处理我们的表达式。先游标加一,此时游标指向“1”。通过captureToEOS方法抓取从当前位置到语句结束内容,即从“1”到分号前的内容(123),此时游标指向“;”。最后返回AssignmentNode实例,其中已解析完成语句内容(变量名a,值123)。
返回到paraseAndExcuteInterpreted方法,通过返回节点实例的getReducedValue方法来处理“a=123”这条语句(通过递归解析子表达式)。AssignmentNode的getReduceValue处理语句两种方式,一种是对已存在的变量,进行操作后,然后返回上下文环境;另一种是对不存在的变量进行创建,然后通过getValue返回。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12
| public Object getReducedValue(Object ctx, Object thisValue, VariableResolverFactory factory) { checkNameSafety(varName ); if ( col) { PropertyAccessor.set(factory.getVariableResolver( varName).getValue(), factory, index, ctx = MVEL.eval( expr, start , offset , ctx, factory), pCtx); } else { return factory.createVariable(varName, MVEL. eval( expr, start , offset , ctx, factory)).getValue(); } return ctx; }
|
这里我们又进入了一个eval,不过这回eval的主角变成了“123”
根据返回的内容创建SimpleSTValueResolver实例,调用getValue方法返回其值,然后压入到ExecutionStatck中。
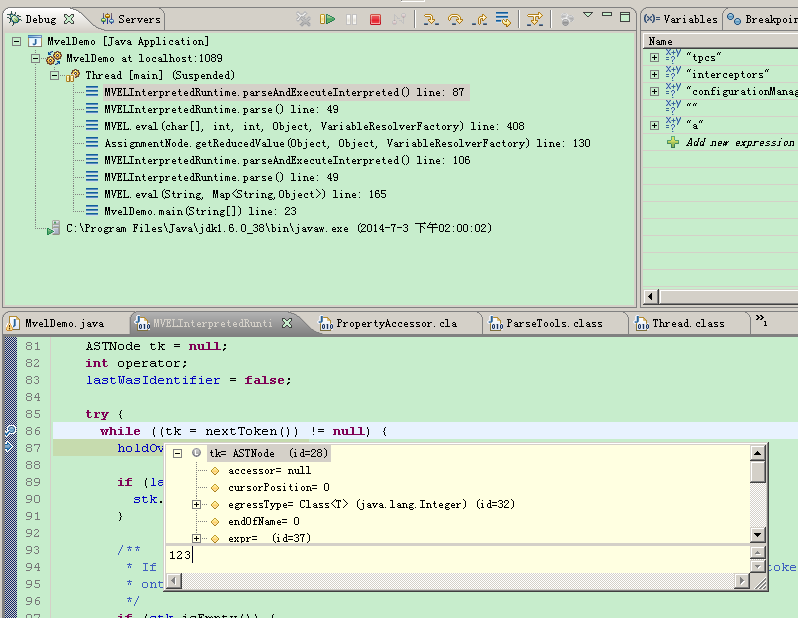
下面继续循环内容,游标向后移至语句截止符“;”,nextToken返回截止节点信息
1 2 3 4
| case ';' : cursor++; lastWasIdentifier = false; return lastNode = new EndOfStatement(pCtx);
|
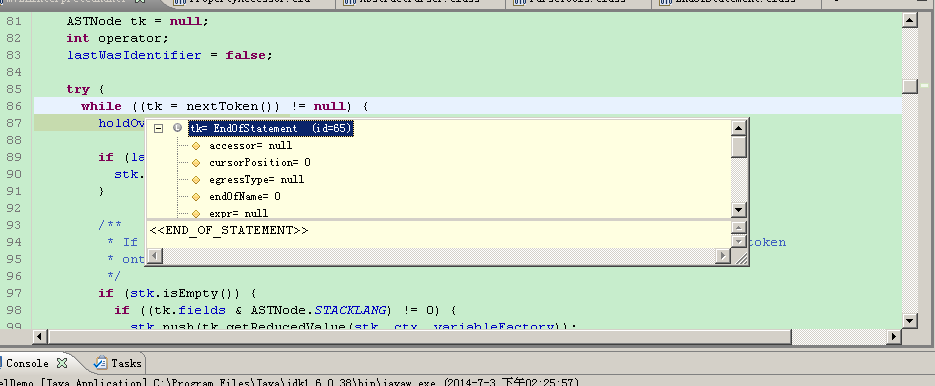
ExecutionStatck不为空(之前已经压入了“123”)则继续向下执行,进入判断操作符分支。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| switch (procBooleanOperator(operator = tk.getOperator())) { case RETURN : variableFactory.setTiltFlag(true); return stk .pop(); case OP_TERMINATE : return stk .peek(); case OP_RESET_FRAME : continue; case OP_OVERFLOW : if (!tk.isOperator()) { if (!(stk .peek() instanceof Class)) { throw new CompileException("unexpected token or unknown identifier:" + tk.getName(), expr, st); } variableFactory.createVariable(tk.getName(), null, (Class) stk.peek()); } continue; }
|
分号属于OP_RESTE_FRAME,并且通过procBooleanOperator方法清空ExecutionStatck等残留信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| case END_OF_STMT: * Assignments are a special scenario for dealing with the stack. Assignments are basically like * held -over failures that basically kickstart the parser when an assignment operator is is * encountered. The originating token is captured, and the the parser is told to march on. The * resultant value on the stack is then used to populate the target variable. * * The other scenario in which we don't want to wipe the stack, is when we hit the end of the * statement, because that top stack value is the value we want back from the parser. */ if (hasMore()) { holdOverRegister = stk .pop(); stk.clear(); } return OP_RESET_FRAME ;
|
然后进入下一循环,读取后面的语句。重复之前的捕获关键字的过程捕获到“NEW”(通过空格捕获到的),通过captureToNextTokenJunction 从当前位置抓取到下一个连接点(junction),此时游标指向“(”(“()”中所包含的内容,应作为子语句所解析,所以“(”之前部分应先解析)。然后根据圆括号之前的内容,构造NewObjectPrototype实例,并以此构建节点,最后返回节点。
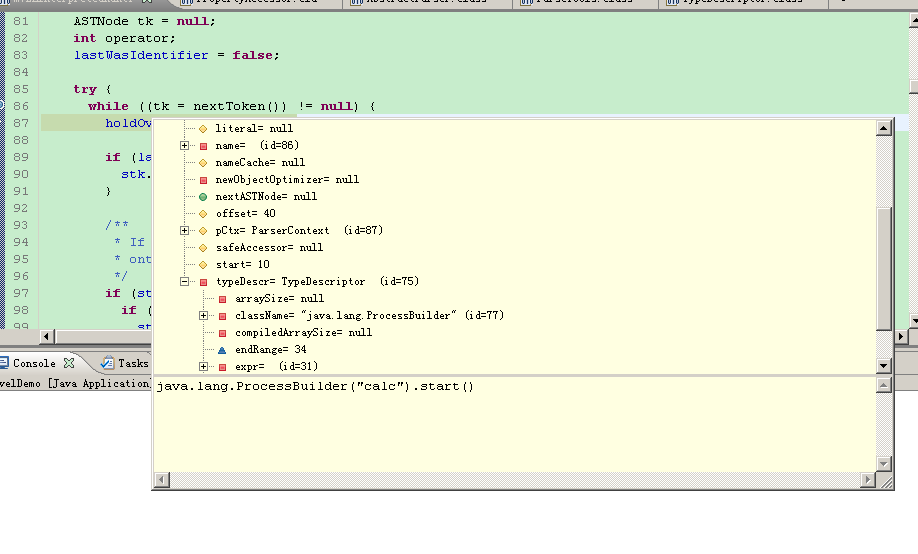
然后进入org.mvel2.ast.NewObjectNode中的getReducedValue,这里“123”那里差不多,使用org.mvel2.MVEL.eval来递归解析圆括号中的内容。就像“123”那样解析,不同的是被双引号包围,所以作为字符串来解析,返回Literal节点。然后压栈,进行一些后续操作,结束操作返回上一层调用(NewObjectNode那里)。
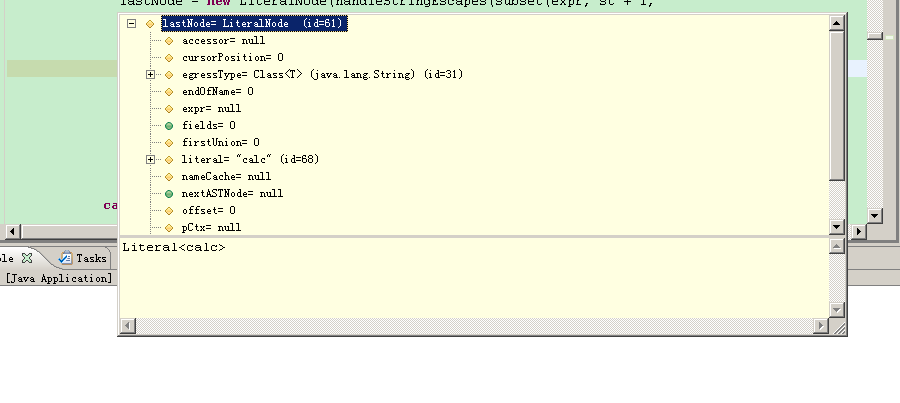
后面就是通过反射构造实例,初始化执行的调用了。这里最需要注意的是org.mvel2.PropertyAccessor这个类,这个类中方法的调用大多是与反射相关的。所以一旦在分析过程中进入了这个类,并且调用了某个比较大的方法,那么很有可能这种MVEL表达式的用法会造成一些强大的破坏,例如这里:
再然后就如同上一条语句那样,检测到语句结束字符“;”,返回上一层,结束解析和执行。
0x03 一些方法功能的记录
AssignmentNode 创建节点实例,解析单条语句中的变量和值,或者方法操作。
balancedCapture 获取(、[分支中的内容。
captureStringLiteral 获取制定包围符中的字符串(if (expr[cursor] == ‘\\‘) cursor++;这句比较有趣)。
1 2 3 4 5 6 7 8 9 10 11
| public static int captureStringLiteral(final char type, final char[] expr, int cursor, int end) { while (++cursor < end && expr[cursor] != type) { if (expr [cursor] == '\\' ) cursor++; } if (cursor >= end || expr[cursor] != type) { throw new CompileException("unterminated string literal" , expr , cursor); } return cursor; }
|
captureToEOS 抓取从当前位置到语句结束。
captureToNextTokenJunction 从当前位置抓取到下一个连接点(junction),即遇到“(”、“/”、“/*”和空白符时终止,遇到“[”则向后偏移至“]”。
captureContructorAndResidual 抓取()中的参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| public static String[] captureContructorAndResidual(char[] cs, int start, int offset) { int depth = 0; int end = start + offset; boolean inQuotes = false; for ( int i = start; i < end; i++) { switch (cs[i]) { case '"' : inQuotes = !inQuotes; break; case '(' : depth++; break; case ')' : if (!inQuotes) { if (1 == depth--) { return new String[]{createStringTrimmed (cs, start, ++i - start), createStringTrimmed(cs, i, end - i)}; } } } } return new String[]{new String(cs, start, offset)}; }
|
PropertyAccessor的getNormal 通过反射执行表达式。